
リアルタイム文法チェックのためのモデルは、年間 5,000 億件以上のクエリを実行すると予想されています
よい文章は編集によって生まれるものだ、と言われてきました。世界中の違いの分かる読み手にとっては幸いなことに、Microsoft は AI による文法エディターを何百万人ものユーザーの元へ提供しています。
他の優れたエディターと同様、「Microsoft エディター」は有益な情報を即座に提示してくれますが、これは Web 版 Microsoft Word の「エディター」の文法校正機能が NVIDIA Triton Inference Server、ONNX Runtime、および (Azure AI の一部である) Microsoft Azure Machine Learning を利用して、このスマートなエクスペリエンスを提供できるようになったためです。
10 月 5 日のデジタルで開催されたGPU Technology Conference の基調講演の中で、NVIDIA の創業者/CEO であるジェンスン フアン (Jensen Huang) がこのニュースを発表しました。
Office で日常的に使う AI
Microsoft は AI の魔法を使って Office 生産性アプリのユーザーを驚かせることを使命としています。時間の節約につながる新しい体験には、リアルタイムの文法提案、文書内での質問への応答 (「完全一致」を超えた文章の Bing 検索のような機能)、文の完成に役立つ予測入力などが含まれる予定です。
こうした生産性向上の体験は、ディープラーニングとニューラルネットワークによって初めて実現できるものです。例えば文法の修正では、ルールベースのロジックを基に構築された従来型サービスとは異なり、Web 版 Word のエディターは文脈を理解して、適切な単語の選択を提案することができます。
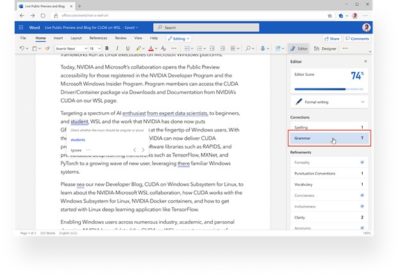
さらに、何億個ものパラメーターを利用する場合があるこれらのディープラーニング モデルは、スケーラビリティを考慮する必要があり、最適なユーザー体験のためにリアルタイム推論も実現する必要があります。Web 版 Word の文法チェックを行う Microsoft エディターの AI モデルだけでも、処理するクエリは年間 5,000 億件以上に達すると予想されています。
これほどの規模で展開すると、ディープラーニングのために莫大な予算がかかりかねませんが、幸いなことに、Azure Machine Learning を通じてアクセスできる NVIDIA Triton の動的バッチング機能やモデル同時実行機能により、約 70% のコストが削減され、1 個の NVIDIA V100 Tensor コア GPU で 1 秒間あたり 450 クエリのスループット、200 ミリ秒未満の応答時間が達成しています。Azure Machine Learning は、必要とされるスケールやモデルのライフサイクル管理機能 (バージョン管理や監視など) も提供しています。
Azure Machine Learning 上の Triton による高性能推論
機械学習のモデルのサイズは拡大しており、モデルのトレーニングと展開には GPU が必須となっています。本番環境への AI 展開に向けて、企業はスケーラブルな推論サービスを提供するソリューションや、複数のフレームワーク バックエンドのサポート、GPU と CPU の最適利用、機械学習ライフサイクルの管理などを求めています。
Azure Machine Learning 内の NVIDIA Triton および ONNX Runtime スタックはスケーラブルで高性能な推論を提供しています。Azure Machine Learning の利用者は、Triton による複数フレームワークのサポート、リアルタイムのバッチおよびストリーミング推論、動的バッチングおよび同時実行を利用できます。
Word での AI を利用した文書作成
作家で詩人のロバート グレーヴス氏は、「良い文章など書けない、書き直して良くなるのだ」と言ったそうです。言い換えれば、まず書くこと、それから編集すること、改善することです。
Web 版 Word のエディターを利用すれば、その両方を同時に行えます。また、エディターは Triton と ONNX Runtime が実現するスピードや幅広い改良を Word で利用する最初の機能ですが、これに続く機能は今後も登場していくと見られます。
GTC で実施される数百のライブ講演やオンデマンド講演へのアクセスは、まだ間に合います。20% オフとなるプロモーション コード CMB4KN を利用して、10 月 9 日までに登録しましょう。